Motivation
The average number of user installed apps on a phone is 40. Each of those apps may request anywhere from zero to more than a hundred permissions. While operating system developers for smartphones have provided users with the access to deny or approve of every single one of those permissions through the native settings app, it is a task often viewed as tiresome, especially by those who are less digitally literate. The research aims to explore the possibility of categorizing users’ diverse privacy preferences into high-level privacy profiles using machine learning and data mining algorithms. This could potentially lead to a more convenient way for people to manage their privacy preferences as a whole.
Data Collection
The data sample was restricted to free apps on the app store. The researchers retrieved the metadata for approximately one hundred thousand free apps from the google play store. They then extracted the permissions requested for each app and performed static analysis on the code to determine the broad functionality of each request with respect to the actual function of the app. For example, they distinguished between a location request for the sake of the functionality of the app and a request for the sake of targeted advertisements. Eight hundred and thirty seven app’s set of permissions were organised into app-permission-purpose triples for the sake of user research. Crowdsourcing through Amazon Mechanical Turk was utilised to analyse the set of data. Each participant was shown the app’s icon, screen shots, and description of apps. They were asked if they expected this app to access certain types of private information and were also asked how comfortable (from “-2” very uncomfortable to “+2” very comfortable) they felt downloading this app given the knowledge that this app accesses their information for the given purposes. Each HIT (Human Intelligence Task) examined one app – permission – purpose triple. Participants were paid 0.15$ per completed HIT. Some HIT’s were eliminated from the analysis pool due to too few responses.
Analysis and Clustering
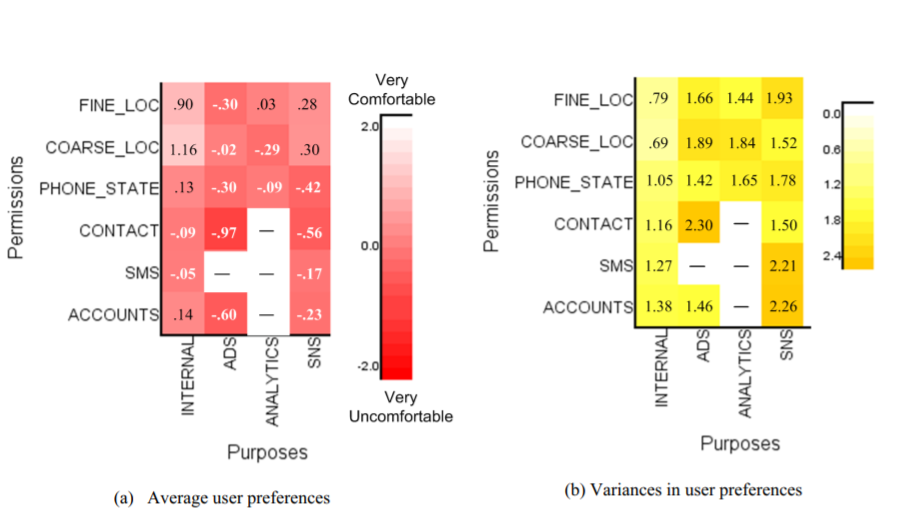
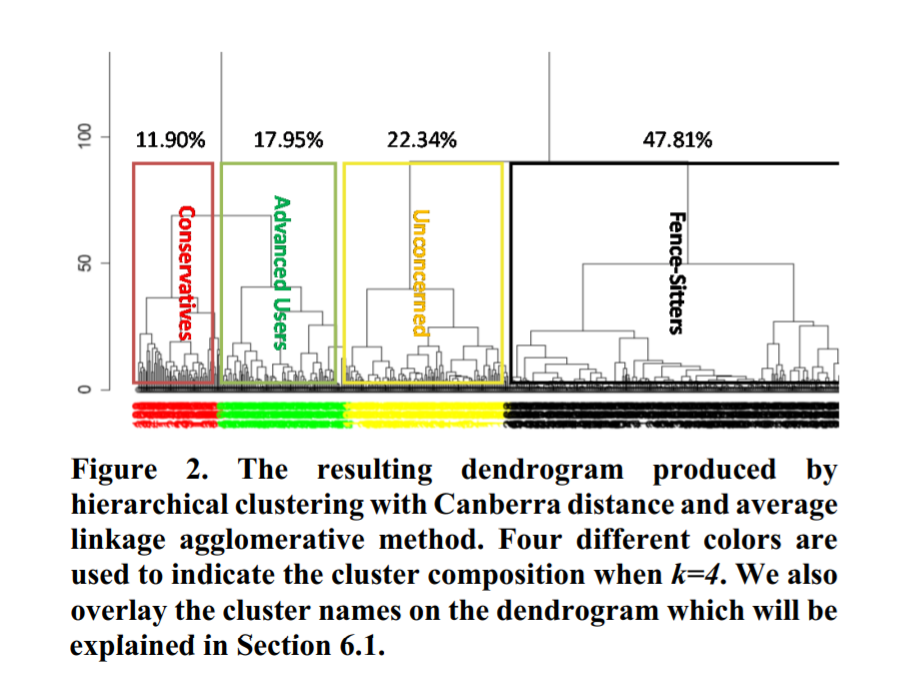
The average comfort for each permission-purpose pair was visualized in a tabular form (darker shades indicate higher values and lighter shades indicate lower values). The high variance amongst the values as shown indicate large diversity in users comfort level for each pair and that there is no ‘one size fits all’ approach to privacy preferences. This data further motivated the research question of whether such preferences can be segregated into broad groups. The comfort-level HIT dataset was preprocessed by filling in some missing values and eliminating pairs that had too few values. After experimenting with multiple clustering algorithms and distance metrics, the researchers fed the dataset into a hierarchical clustering algorithm (agglomerative) using Canberra distance as the distance metric. The best results were achieved when k was set as four, resulting in four apparent profiles. They were then given names based on each cluster’s outstanding privacy preference qualities.
Results
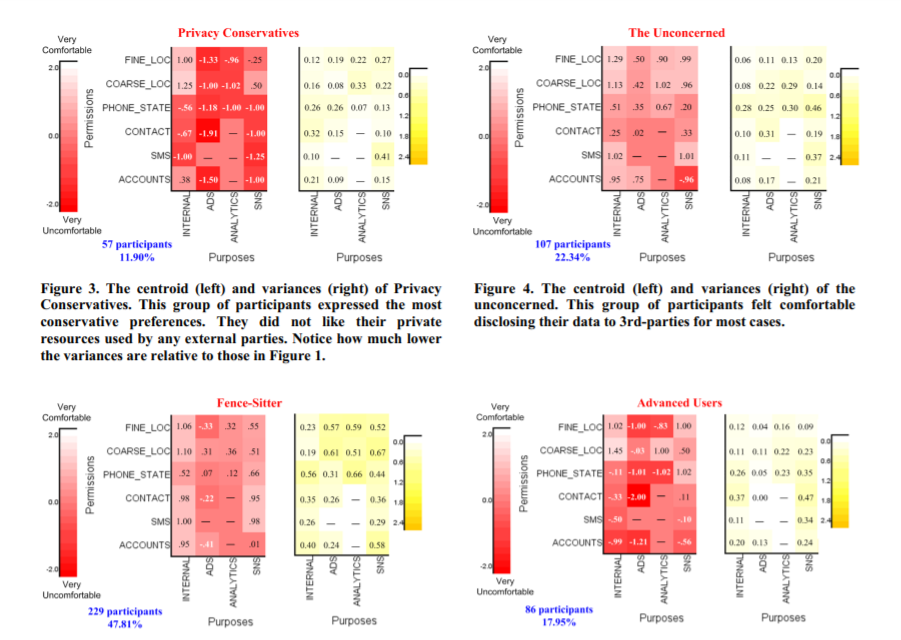
The centroids of each cluster were taken and the variances within each cluster were computed and visualized as well similar to the initial dataset. Variances were much lower amongst data as compared to when the total averages were considered, the highest variance being 0.66 in this case. The researchers broadly categorized the four clusters as follows :
1. The (Privacy) Conservatives :
They represent 11.90% of the participants . Compared to the heat maps of other clusters, this cluster has the largest area covered in red and also the overall darkest shades of red (indicating the lack of comfort granting permissions). In general, these participants felt the least comfortable granting sensitive information and functionality to third parties (e.g., location and unique phone ID).
2. The Unconcerned :
This group represented 23.34% of all the participants and forms the second largest cluster. The heat map of this privacy profile has the largest area covered in light color (indicating high comfort). In general, participants who share this privacy profile showed a particularly high level of comfort disclosing sensitive personal data under a wide range of conditions, no matter who is collecting their data and for what purpose.
3. The Fence-Sitters :
Participants in this cluster were labeled as “Fence-Sitters” because most of them did not appear to feel strongly one way or the other about many of the use cases. This cluster represents nearly 50% of the population. This group of participants felt quite comfortable letting mobile apps access sensitive personal data for internal functionality purposes, but had a more neutral outlook otherwise.
4. The Advanced Users :
The advanced user group represents 17.95% of the population. This group of participants appeared to have a more nuanced understanding of what sorts of usage scenarios they should be concerned about. In general, most of them felt comfortable with their sensitive data being used for internal functionality and by SNS libraries. One possible reason of why they felt okay with the latter scenario is because they still have control over the disclosures, since these SNS libraries often let people confirm sharing before transmitting data to corresponding social network sites. In addition, this group disliked targeted ads and mobile analytic libraries, but still felt generally agreeable to disclosing context information at a coarser level of granularity (for example coarse location).
The researchers then proceeded to adapt these clusters for a predictive model, modifying the HIT’s to a simple “Rejct”,“Accept” and “Prompt” inputs. This model yielded an accuracy of 79% as compared to the initial models 56% and a user burden of 36% as compared to the initial models 87%. The numbers were obtained over 10 runs under different splits.
Critique
I thoroughly enjoyed reading through this paper. It was clear and concise in it’s limitations and its potential and was visualized in a comprehensible manner. However I believe the future of research in managing users’ privacy preferences should be led less in the direction of automation and more on how to make it easier and more convenient for users to manage their privacy themselves. I think it would be interesting to experiment with gamifying a task like managing your privacy preferences. Perhaps designing tools to educate users about the function of certain permission requests could be explored as one edifying aspect of this paper was the effect of knowledge of the function of the permission request.